It's O.K. It's Just Us Two Rows Joined: Vertical Partitioning Or When a 1x1 Table Relationship Makes Sense
From a theoretical sense, there would never be any reason to segregate data which has a one to one relationship. Multiple tables were meant to allow one datum to link to multiple others minimal or no duplication. Unfortunately, practice and theory often diverge and when applying techniques in real world applications, and scenarios arise which are less than perfect and so theoretical absolutes are often left behind. Because of this, in certain scenarios, one to one table relationships can be advantageous to keeping all data in a single table.
Security
This is probably the easiest example to show day to day impact on segregating data. It’s very easy to restrict access to a table, but it’s very hard to restrict access to a single column. Say the column is something like employee salary information or customer social security numbers (well you’re encrypting these anyway right?), the organization may not want or even allow anyone but a select set of individuals to view the information. There are a number of ways to handle this scenario when it’s in the same table, like not accessing the table directly by enforcing a company policy that applications may only retrieve data through views or stored procedures. This is a great approach, but it has possible flaws.
- It may not be possible. If you are adding the field to an existing table, there may already be legacy applications using direct access to the table and worse yet may use SELECT *. The organization would need to spend significant amounts of time and money to refactor all the applications to remediate the problem. Since this is most likely the costliest solution, and there are other alternatives to solving the problem, it probably isn't the best choice of action.
- Security is only as good as the organization enforcing it. It’s easy to say “Under no circumstance will this occur.” The problem is that most people are busy, and there are always scenarios where “an application can’t use stored procedures or views.” In reality, this probably isn't true, but organizations always try and move at the fastest possible pace, and instead of taking time to think of an alternative, someone grants an elevated level of access. Should the admins do this? No, but when people get overworked things slip, and, in truth, they don’t deserve all the blame in making a mistake when an organization places them in this position. Regardless of who’s at fault, it’s still a problem and needs to be avoided.
Performance
Performance is a second reason for one to one relationships and can have just as significant of an impact in using them. Often when looking at performance, it’s necessary to look at all the scenarios where table size causes an impact. With small tables, everything is fast, but a small performance oversight when starting can easily become a large problem later on.
Data Access and Locking
Every time SQL Server updates data, it has to lock the updated row. Normally, this is a pretty fast operation, but if the row in question is part of a larger transaction, access to it becomes problematic. The longer it takes to update, the longer other queries must wait before accessing the data, and if this happens frequently, it can severely limit the speed of applications performing actions on that table. There are other solutions to this problem such as using NOLOCK, but this removes the guarantee the accessed data is accurate. If an update is running and something uses NOLOCK to access the data and the update aborts due to an error, the accessed data could be inaccurate as it might contain information from an update which wasn’t committed. (Consider a query to access your bank account information using uncommitted reads. Are you sure you want your account balance to possibly be inaccurate?)
Depending on the scenario, a better solution might be to partition the data into two tables: one where data that changes minimally and can be queried without fear of table locking, and a second table housing the columns which update frequently and lock rows:
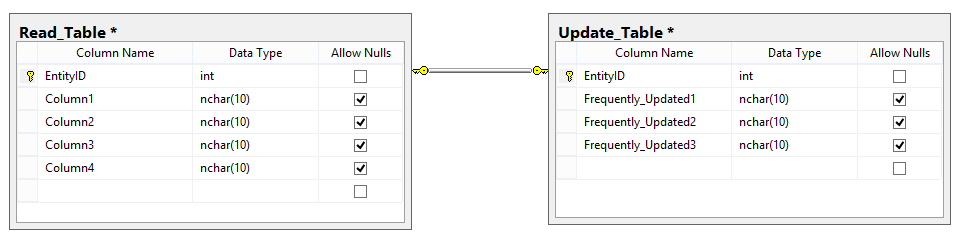
This can be taken to an extreme and is not ideal for all situations, but in scenarios where time consuming updates occur and it slows down query access to other columns, it’s an efficient way of ensuring both data integrity querying and increasing application performance.
Triggers
Triggers can be set to fire when anything changes on a table, and this is true even when the exact same value is placed in the cell. Take the following table as an example:
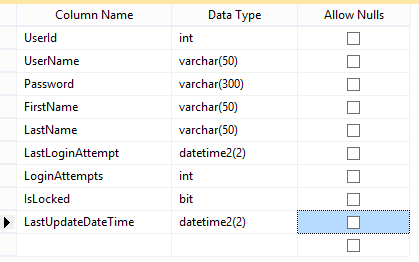
Let’s say you want to track every time someone changes their username, first name, last name, or password. In this scenario, you could just have the application log the changes in an audit table. That’s a good approach, but it’s limiting in that it assumes only one application handles user management. You could have the user update SQL code placed in a stored procedure and have all applications call it. This assumes that
- All developers know (and care) to use the stored procedure
- People administrating the database and accounts in production know to use the procedure when updating accounts outside of the application. (Yes, it is true this probably shouldn't happen, but in reality how often does that stop people who are trying to fix things as fast as possible to keep the organization running?)
This leaves using a trigger which fires and logs updates every time the table changes. The problem with this is that the trigger will fire every time anything changes. Even if the trigger is designed to ignore unnecessary fields and only to insert data into the log table when certain fields change, it still has to run on every update creating unnecessary overhead. By changing the table structure to:
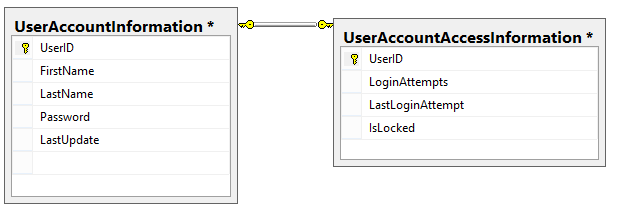
this allows the trigger to fire only when updating rarely changed values and reduces the unnecessary overhead of having it evaluate and possibly log changes it’s not concerned with.
Backup and Restore
Operational Logistics are often something that most people aren’t concerned with when building applications, but they should be. Designing a series of tables and not thinking about the target environment can causes long term problems if they don’t understand the physical layout of the network.
A number of companies back up their production databases and restore them into test and development environments. This allows developers to understand what the real data looks like and ensure they are writing code against the production database schema. Production and development database structures eventually diverge (i.e. abandoned development code, quick fixes in production to avert crisis, etc.) meaning that developers aren’t writing code against the actual schema unless they’re updated to match production. To solve this problem, organizations back up the production databases (and hopefully scrub out sensitive information), and restore them to the test environments.
Organizations which house all their environments in a single location, moving large databases often isn’t an issue,  but not everyone has that luxury. Let’s say your development team is in Indiana, your production applications are in Vermont, and your Test Systems are in North Carolina.
but not everyone has that luxury. Let’s say your development team is in Indiana, your production applications are in Vermont, and your Test Systems are in North Carolina.
Moving a small database between them would be relatively easy, but this can become a problem as the database grows. Either the time to transfer the databases increases or the expense of having a larger connection between the centers does.
There are ways to help reduce this issue. The easiest is to
- Backup the database
- Restore it to someplace else in the same datacenter
- Remove the data which isn't necessary for the test environment and compact the database
- Move the smaller database to the other environments.
This approach doesn’t require tables to be split, but it helps. If you have something like,
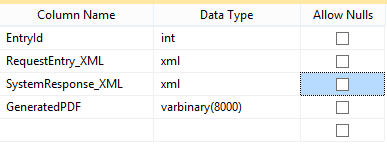
and you want to keep the XML columns for development to analyze but don’t care about the binary PDFs, you can update each PDF entry to NULL. Depending on the size of the table this may be trivial, but if you have something like 10 million records, that could take some time. Alternatively, it’s much easier to segregate the data like so
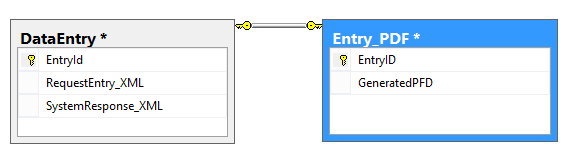
and use TRUNCATE TABLE (or DROP TABLE and then recreate it). A small change to the structure can save a huge amount of processing time.
Partitioning
Depending on the database engine, moving data to different tables to partition data may not be necessary, but to those which it is, segregating data can have a marked performance gain. Most people think of a server having multiple disks, but it’s uncommon to immediately think of a server having access several different types. This is an idea which is gaining popularity and is even moving to desktops, where there are faster drives, say a solid state drive, which are used to store commonly accessed data, and slower drives, maybe a 7200 rpm spindle drive, to house data where speed isn’t an issue. High performance drives are often smaller and more expensive, and because of this, it’s necessary to use them as efficiently as possible. With modern databases, partitioning columns to different disks is possible, but depending on their layout and applications access them, it might be tricky, and with legacy systems this may not be an option. With this in mind, moving large, rarely accessed, data to a different table and moving to a slower drive allows the database to access the other data faster and increases application performance.